
Tensorflow.js 海量图标,毫秒级识别!

背景
前端开发过程中,需要还原设计稿图片中的图标,大多时候设计稿中的图标没有对应的 type 字段,如果肉眼从几百个图标中寻找,用户体验非常差。
所以,笔者去年在 Ant Design 开源项目中提交了一个 Pull Request,该 PR 基于深度学习技术贡献了一个截图搜 Icon 的功能,用户直接对设计稿或任意图片中的图标截图,点击或拖拽或粘贴上传,就可以搜索到匹配度最高的几个图标以及对应的匹配度。而且,所有识别工作都是在前端进行的!
效果如图所示:
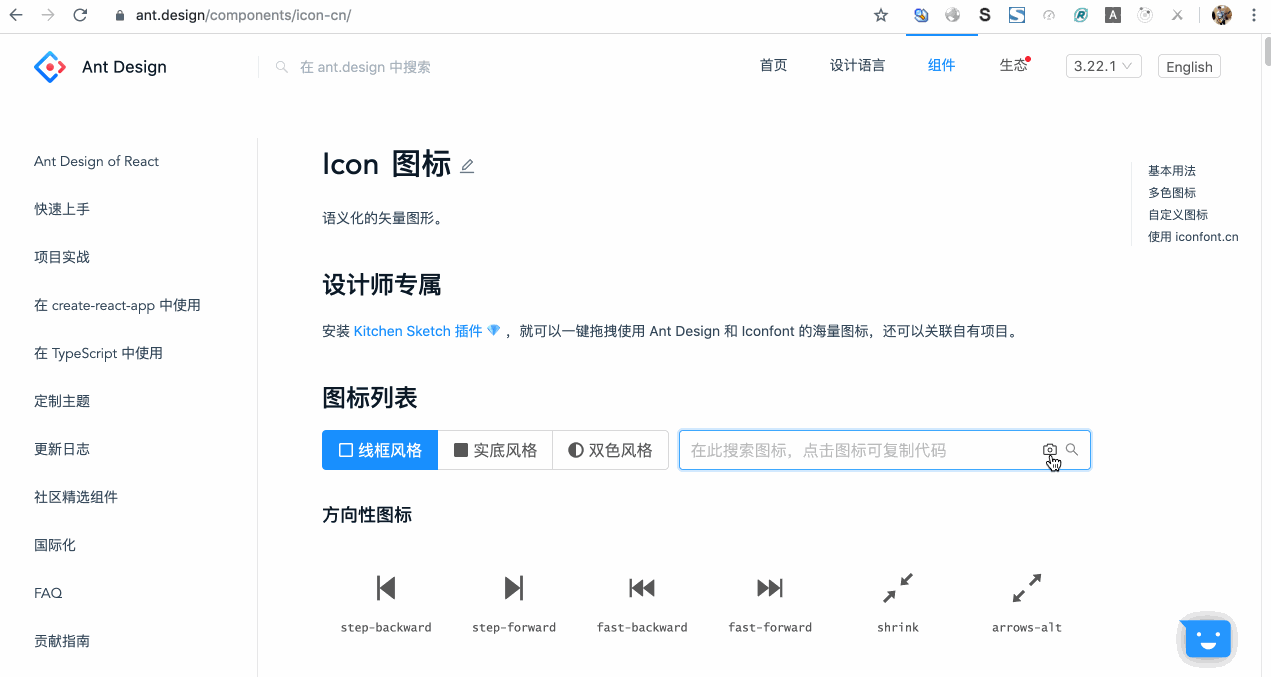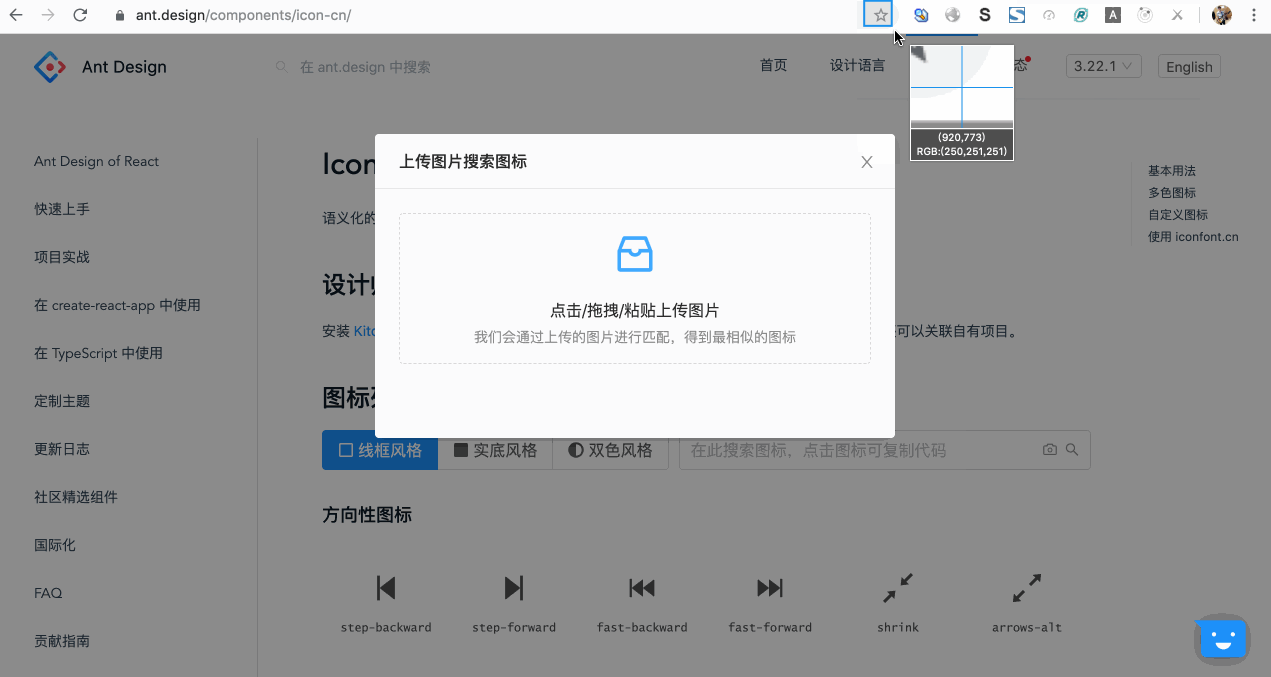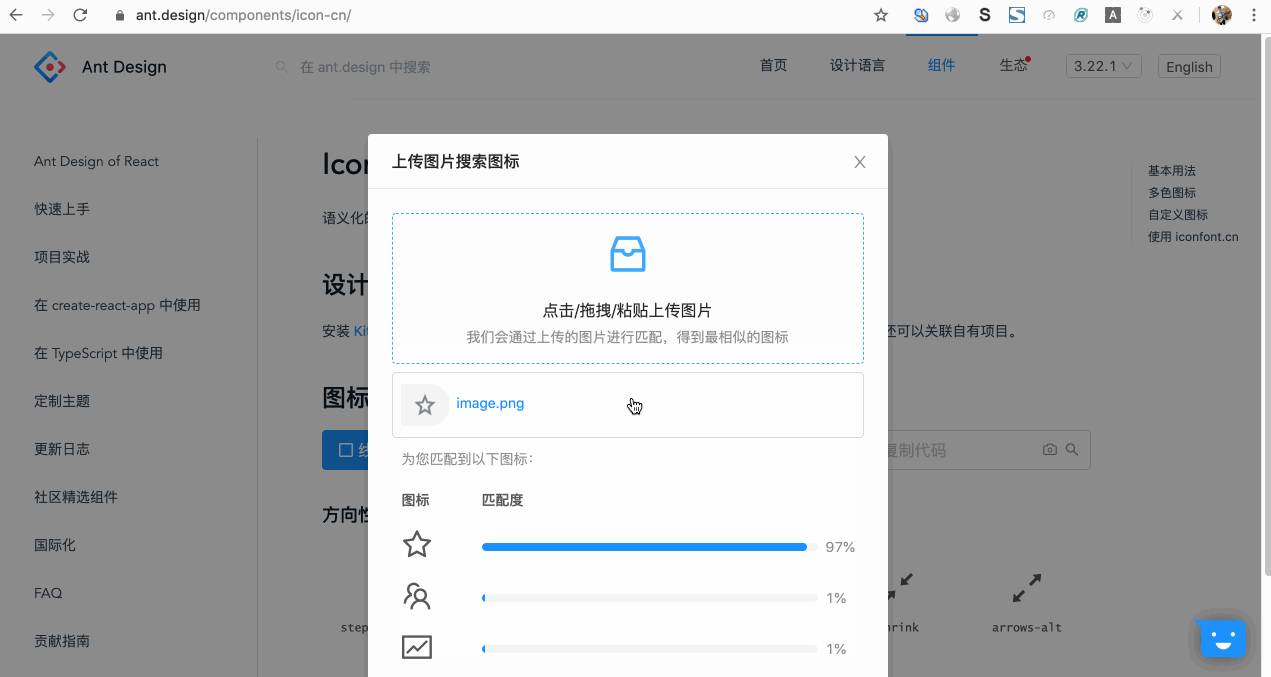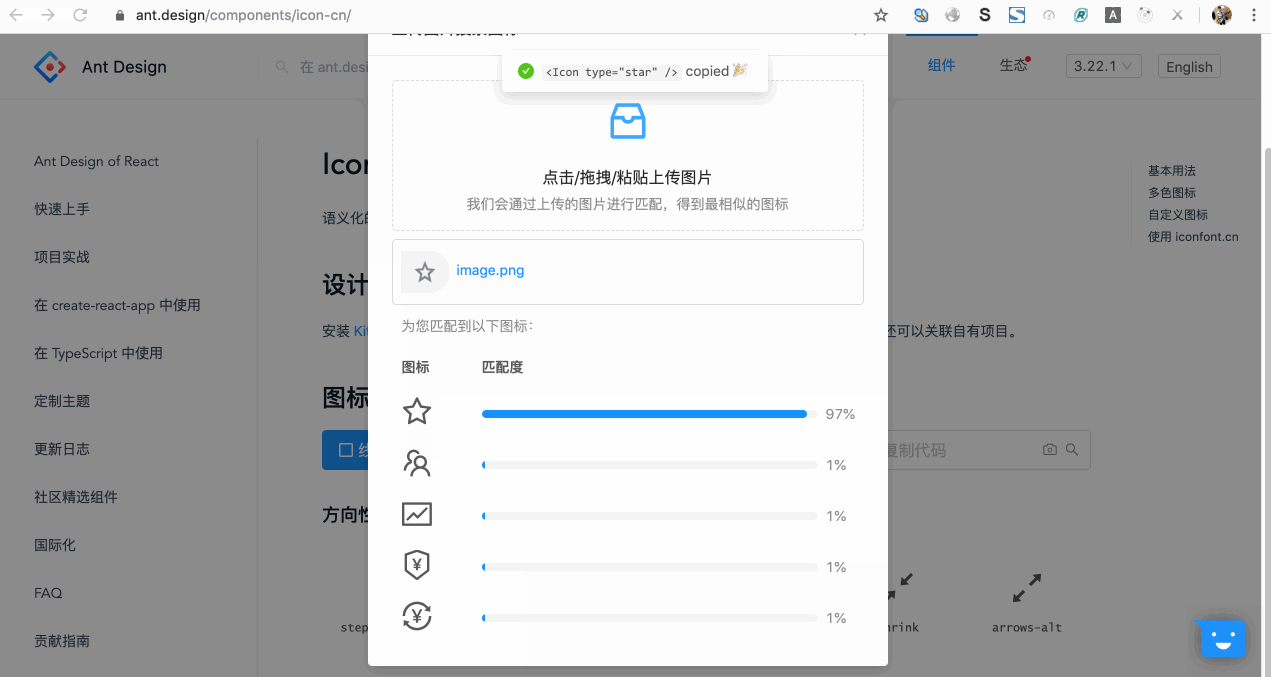

也可以到官网直接体验:
https://ant.design/components/icon-cn/
那么这个技术是如何实现的呢?本文将会逐步揭秘:
- 深度学习简介
- 样本生成
- 模型训练
- 模型压缩与转换
- Tensorflow.js 识别
深度学习简介
前面提到过,这个功能是基于深度学习来做的。那么什么是深度学习呢?深度学习是机器学习的一种,而机器学习可以简单理解为:
机器学习是对能通过“经验”自动改进的计算机算法的研究。
关键词就是经验。其实人类很早就会使用经验来解决问题了。比如,早在中世纪,有人就通过测量16位男子的平均脚长来判断所有男子的平均脚长。


再举个例子,给你很多身高体重的数据,再给你一个人的身高,你能不能估摸出他的体重呢?

当然可以!你可以先算出上图的公式,y = ax + b 中的 a 和 b,然后算一下就可以了对吧!简单的小学数学题而已。其实在机器学习里 a 叫权重(weight),b 叫偏置(bias)。这已经是机器学习了,更具体来说是线性回归。
既然机器可以学习数字的规律,那么如果我们把图片/语音/文字都转为数字,让计算机去学习,那么计算机能不能识别出他们的规律呢?当然可以!不过,背后的模型就复杂的多了。
图片分类


语音助手


我们使用的就是一种名为卷积神经网络的深度学习模型,来进行图标截图的分类工作。
不管是简单的线性回归还是复杂的深度学习,都是从“经验”中学习。那么这个“经验”呢,在机器学习里被称为“样本”。所以,首先我们要生成给机器学习的样本。
样本生成
在这次图标分类任务中,样本包含两部分:
- 图片
- 图片对应的标签
标签指的是图片的分类名称,比如你想识别图片中是一只猫还是一只狗,那么猫和狗就是标签。
研究表明,样本越多,深度学习模型学得越好。所以我们采用了样本页面 + Puppeteer + Faas 的方式,快速生成了几万张图标图片以及对应标签。具体是怎么做到呢?
- 编写样本页面:新建了一个前端页面,这个页面只渲染了一个 Antd 的图标,但是,这个图标可能是三百多个 Antd 图标的任何一个,不仅如此,连图标的尺寸、颜色、位置等都随机化渲染。
- 使用 Puppeteer 循环截图:样本页写好了,我们用 Puppeteer (一个无头浏览器)打开这个页面,并自动循环进行刷新-截图的操作,生成了几万张图片。
- Faas 并发:由于在 PC 上生成几万张图片太慢了,所以我们希望可以在100台机器上并发截图,于是使用了阿里云的函数计算(FaaS),同时开了100个实例进行并发截图,实测每分钟可以生成 2万张图片。
如此以来样本就有了。


模型训练
样本有了之后,就可以开始进行模型训练了。我们使用的是 Tensorflow 这个框架,官网有个基于迁移学习的图片分类例子,直接下载下来,运行时候,参数指定为我们刚生成的样本就可以了。
https://github.com/tensorflow/hub/tree/master/examples/image_retraining
在 PC 上就可以训练,速度虽然不快,但是吃个午饭就差不多了!
不过,值得一提的是在阿里云还有 PAI 服务,上面有现成的图片分类算法,还提供了 GPU 可以加速训练。笔者虽然没有使用 PAI 上图片分类算法,但是把 Tensorflow 的代码部署到 PAI 上训练了,速度飞快!
模型转换与压缩
模型训练好之后,就可以直接识别了,但由于是 Python 代码,所以必须部署到服务器上,才能给大家用。这样有很多弊端:
- 服务器费用:部署模型需要服务器,而 Ant Design 是开源项目,我们不愿意承担任何线性增加的费用。
- 识别速度:服务器是中心化的,距离较远的国外用户,使用起来必然速度会受影响。
- 稳定性:Ant Design 约有十几万开发者使用,如果服务器出现问题,稳定性堪忧,影响面太广,担心晚上睡不好觉。
- 安全:Ant Design 网站是静态公开的网站,没有任何认证和授权,如果开放接口,必然有一些安全问题。
出于以上考虑,我们打算将模型转为 Tensorflow.js 的模型,让用户下载到浏览器中进行识别。这样有很多好处:
- 边缘计算:每个用户都有一台电脑,电脑上都有 GPU,我们的模型下载到浏览器后可以使用海量用户的电脑 GPU 算力,节约了服务器费用,也不用担心各种服务器攻击和服务器稳定性问题。
- 识别速度快:由于模型被下载到了用户的浏览器中,所以识别过程没有网络传输,几乎是实时的。
模型转换与压缩使用的都是 tfjs-converter:
https://github.com/tensorflow/tfjs/tree/master/tfjs-converter
我们使用的是 mobilenet 进行迁移学习,本来模型为 16 M,经过压缩变为 3M 左右,发布到了 jsdelivr cdn,全球加速,永久有效。
Tensorflow.js 识别
模型也有了,现在只需要编写一些 Tensorflow.js 代码就可以进行识别了。
首先,加载模型文件:
const MODEL_PATH = 'https://cdn.jsdelivr.net/gh/lewis617/antd-icon-classifier@0.0.1/model/model.json';
model = await tfconv.loadGraphModel(MODEL_PATH);
然后,将图标截图转为 tensor:
tensor 是一种数据结构,很像多维数组,在 Tensorflow 中,模型输入输出的都是 tensor,所以不管是训练还是识别前,都需要将数据转为 tensor。
// 从图片转为 tensor
const img = tf.browser.fromPixels(imgEl).toFloat();
const offset = tf.scalar(127.5);
// 把一张图片从 [0, 255] 归一化到 [-1, 1].
const normalized = img.sub(offset).div(offset);
// 更改图片尺寸
let resized = normalized;
if (img.shape[0] !== IMAGE_SIZE || img.shape[1] !== IMAGE_SIZE) {
const alignCorners = true;
resized = tf.image.resizeBilinear(
normalized, [IMAGE_SIZE, IMAGE_SIZE], alignCorners,
);
}
// 更改tensor的形状,使其满足模型要求
const batched = resized.reshape([-1, IMAGE_SIZE, IMAGE_SIZE, 3]);
然后,进行识别:
pred = model.predict(batched).squeeze().arraySync();
// 找出匹配度最高几个类别
const predictions = findIndicesOfMax(pred, 5).map(i => ({
className: ICON_CLASSES[i],
score: pred[i],
}));
就可以得到最终结果了!
完整代码:

