
GPT-3 袭来,前端又要失业?谈谈如何实现智能切图


3 年前,智能切图项目 pix2code 轰动了前端界,它的效果非常惊人,只需要输入一张图片就能生成前端代码,有了它任何人都能切图了,还要啥前端?看起来前途无量。
不过和绝大多数论文一样,这个项目出道即巅峰,后来再也没升级和优化,一直停留在最初的状态,根本没法用,渐渐就被遗忘了。
但最近 GPT-3 再次挑战前端,这次是直接输入自然语言就生成 HTML 代码,这下连图都不要了,说说话就能生成页面:
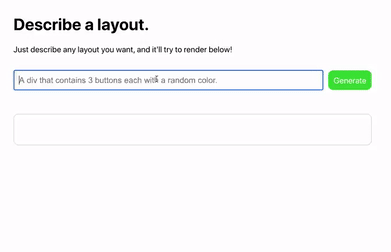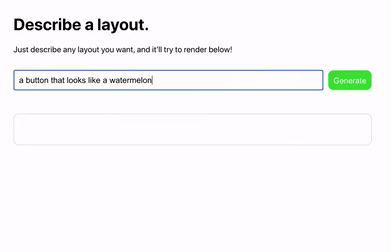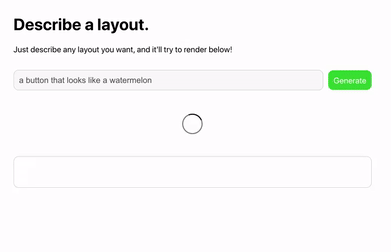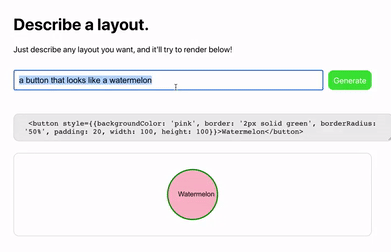
于是国内有媒体直接评价说「前端群体心情估计比较复杂,特别是刚入门的同学们可能会再三思考:我奋斗下去能比 AI 强吗?」。。。
作为「前端群体」中的一员,我也很关心自己的饭碗会不会像棋牌类游戏那样被 AI 抢走,所以本文就来分析一下 GPT-3 及各种可以实现智能切图的技术。
有哪些 AI 技术可用
首先通过各种书籍和开源框架,我整理了一下目前机器/深度学习能做的各种事情:
- NLP 相关,分词、词性标注、实体识别、语音模型、情感分析、标签、文本分类等。
- 生成相关,比如生成文本和生成图片。
- 判别相关,这包括:
- 图像识别,图像识别,OCR、证照、车牌、动物/植物、人脸等。
- 图像/文本分类,判别是广告、黄反等。
- 无监督相关的,聚类、异常检测。
- 强化学习,训练出能根据环境进行决策的机器人。
这里面看起来最相关的是「生成文本」,因为代码可以理解是一种文本,基于什么来生成?可以是文本或图片,我们就先来讨论这两种技术:「基于文本生成文本」和「基于图片生成文本」。
基于文本生成文本
从自然语言生成 HTML 代码就属于一种文本生成文本技术,前面那个例子是基于 GPT-3 实现的,什么是 GPT-3?目前网上的文章分为两个极端,一种是普通媒体把它吹得无所不能,另一种是业内人士写的技术分析,陷入到各种向量计算细节里。
这里我用自己的理解来解释一下,GPT-3 是一种语言模型,目的是为了能总结出语言中的各种内在规律,比如「语法」是一种人为总结出来的语言规律。早期自然语言处理也是通过复杂的人工规则来实现,但日常语言中经常有各种特例,所以这个规则越来越复杂,难以维护。于是后来基于概率的模型胜出了,它不需要人工规则,而是自动基于大量文本统计出这个内在的语言规律。
GPT-3 这类模型的训练方法是首先初始化一堆随机数字(参数),选取一段文本,去掉最后一个词,然后让模型预测这个词是什么,如果错了就根据差距更新那些随机数字,直到最终训练完成,最终得到的这一堆数字就是语言模型了,可以拿它来去做文章生成、翻译等功能。
以 GPT-3 为例,它参数是以 96 个 transformer 解码器连接起来的,参数总数达到 1750 亿个,训练时输入了 45T(过滤后570GB) 文本,这些文本 88% 来自网页抓取,16% 来自书籍,3% 来自维基百科,整个训练据说花费 1200 万美元。
怎么用 GPT-3 来实现自然语言转代码呢?其实这个问题和翻译是一样的,只需要准备好大量一对一的自然语言和代码(我觉得这里最好用 DSL 来保证生成准确性),然后基于 GPT-3 做 fine-tuning 就行,不过 GPT-3 需要申请,感兴趣的话可以拿 gpt-2 试,或者 paddlepaddle 的机器翻译也能做类似事情。
不过这种方式没法用,因为要用文本描述整个页面太麻烦了,而且说不清楚,比如「一个红色的按钮」,红?有多红?这种感性的差别要怎么描述?普通用户恐怕会直接一句「给我来个高端大气的首页」。。。文本转文本取代前端不现实,所以这次前端依然不会失业。
尽管烧了那么多钱,在我看来 GPT-3 可能是这个领域最后一次挣扎了,比如论文中提到的 LAMBADA 测试,参数从 130 亿到 1750 亿对于准确率的提升很平缓,只提升了 2% 左右,到 72%,而人类能轻松做到 98%,按这增长曲线要接近人类得烧多少万亿?后面的投入性价比越来越低,没什么意义。
从底层实现来看,它依赖文本来训练,这虽然省去了人工,但文本自身有极大限制,使得以后无论怎么优化算法都没用,文本有什么限制呢?我想到以下几点:
- 文本作为一种知识的表述方式是有缺陷的,比如丢失了语气、强调等,比如「爱上一个人」,强调不同的字是不同意思。
- 同一个名词有可能既相似又完全不同,比如「亚瑟」,可以是传说中的国王、Saber、或者出门带霸者重装的战士,你如果没看过 Fate、没玩过王者荣耀,都不知道后面两个说的是啥,单从文本里是无法体会到的。
- 知识是网状结构,而文本只能线性,因此知识转成文本的时候就必然会丢失信息,比如这篇文章原本由各种相关联的知识组成,为了用文本写出来,我只能删减部分内容,让知识点变成线性的,不然写起来太啰嗦了根本写不完。
- 根据自动计算的方式,只能得到「相关性」,无法解释因果,现在 GPT-3 虽然看起来有各种各样的应用,比如文章生成、智能问答、翻译、分类等,但其实都是在算相关性,离智能差远了。
- 基于概率意味着小众被无视了,目前的文本绝大部分是网文,这导致拿来生成小众的技术文章效果很差。
尽管无法取代前端,但这项技术在代码辅助方面很有用,我现在每天写代码用的 TabNine 就基于 GPT-2,帮我少敲了很多键盘。
基于图片生成文本
既然「文本生成文本」没法用,那直接基于图片生成文本呢?这个技术在机器学习中有个方向叫 Image captioning,也就是给图片配文字,Facebook 用它来生成图片的 alt 文本,让失明的人也能知道图片是什么,Google 也做过这方面的研究,还将模型开源出来了:


这个技术用在切图上,只需要将生成英文改为生成 DSL 就行。
Google 那个图片编码使用的基于 CNN 的 Inception V3 模型,文本生成使用 LSTM。而 pix2code 使用的也是 CNN+LSTM 方式,它的 CNN 网络是自己设计的,类似 VGG,技术上很相似,所以在我看来也属于配文字这个领域的。
和 pix2code 类似的项目还有 Screenshot-to-code,同样是出道即巅峰,12.7k 的 star 令人羡慕,但它最后的更新时间已经是 2 年前。
看起来这个领域也没有更好的方案了,LSTM 和 CNN 都是 20 多年前的技术了,我认为 LSTM 不适合用来生成代码这种有层次结构的文本,而 CNN 也有很大的限制,它有平移不变性(translation invariant),适合用来做图像识别,但对于设计稿这种位置重要性很高的图片就不合适了,比如文字左对齐和居中是明显不一样的,因此只用 CNN 提取的特征并不适用于切图场景,必须结合其他技术来解决位置问题。
从这个领域著名的 COCO 榜单上看,第一名是腾讯,但没有相关论文,第二名是这篇论文,它使用了用于目标检测的 R-CNN 技术来优化,但这样依然对位置不敏感。而且这个榜单里的论文是 2017 年的时候集中出现的,之后就没有更好的了,因此这个方向短期内不可能取代前端。
说到图片相关的生成技术,就不得不提 GAN,它贡献了大量吸引眼球的新闻,比如:
- 生成人像图片、二次元老婆 https://www.thiswaifudoesnotexist.net/,这些多是基于 StyleGAN,还有一个专门生成人像的网站 https://generated.photos/。
- 超分辨率技术,可以图像高清放大,比如专门针对二次元的 waifu2x,还有 igapixel AI,这个非常实用。


- 将草图转成逼真图像,比如 pix2pix 类的技术。

尽管 GAN 有各种眼花缭乱的应用,但仔细看几乎都是图像转图像,比如穿衣和脱衣本质是一样的,只是对换了一下训练的图。切图的目的不是生成另一张图像,而是生成代码(文本),但 GAN 并不能用来生成文本,核心原因在于文本是离散的,不可导,而 GAN 的原理就是将判别器 D 和生成器 G 之间差距的导数传递回去,而不可导就无法传递,就没有训练方向,不会有什么结果,因此虽然后续还会出现基于 GAN 的吸引眼球应用,但不包括切图。
图像识别技术
既然直接基于图像生成代码难以实现,我们就退一步,使用图片识别技术,分析出图片中的区块,然后再进一步提取出组件来生成页面。
还是看一下目前机器学习能做什么,图像识别常见的几种应用是:
- 图像分类(Image Classification)
- 物体检测(Object Detection)
- 语义分割(Semantic Segmentation)
- 实例分割(Instance Segmentation)
关于这几种应用的区别,我觉得最直观的是下面这张图:
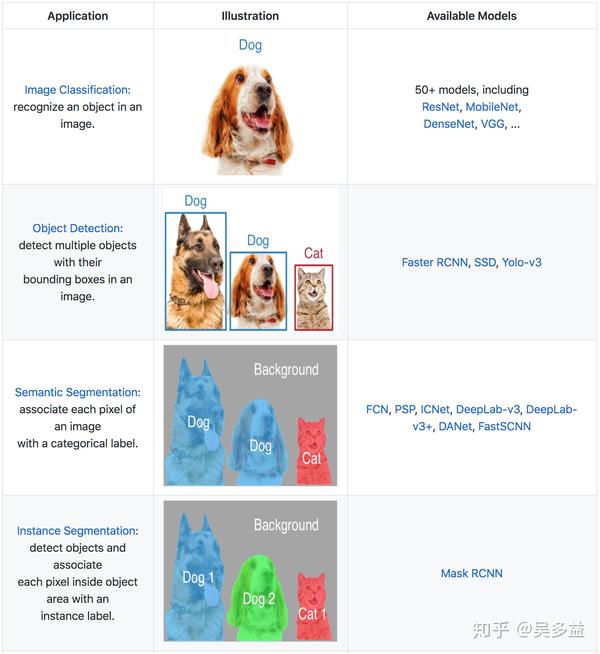

既然目的是分析出图片中有哪些组件,就适合用后面三种算法,这些算法在大部分深度学习框架中都有实现,比如 PaddlePaddle 的模型库。
在这个方向上,airbnb 尝试过基于草图生成代码,就是识别出每个的区域是什么,然后在那个区域放组件。微软的 ailab 也开源了一个 Sketch2Code,其实它本体是 Azure 的软广,具体模型的训练和线上预测都是直接使用 Azure CustomVision 的服务,这个开源项目什么核心代码都没有,主要用于骗不明真相的群众点 Star,但可以看到它是如何标注的,就是那个 dataset.json 文件中,分析一下可以知道一共有 149 张图片,标注了 2001 处,所以估计这个项目 90% 的时间是在做标注。
以 Sketch2Code 为例,输入一张设计图,如果识别成功,将会得到如下:
[{
"TagName": "Image",
"Region": {
"left": 10,
"top": 20,
"width": 200,
"height": 200
}
}, {
"TagName": "Label",
"Region": {
"left": 10,
"top": 20,
"width": 50,
"height": 20
}
}, {
"TagName": "Input",
"Region": {
"left": xxx,
"top": xxx,
"width": xxx,
"height": xxx
}
}]可以看到是绝对定位方式,不过 Label 似乎没提取出内容,可以根据位置取出图片,用 OCR 识别具体文字,有了这些信息,相信你也能写个识别图像生成 HTML 页面的应用了,只要你有耐心做好足够多的标记,就足以让周围同事震惊,但千万别演示太多次。
因为你很清楚这本质上就是个模式识别,离大众心中的人工智能差远了,随便找个画风奇特的草图肯定歇菜,只能通过不断加标签让系统”记住”这些图形。
然而即便花了大量时间标注,它离可用依然很远,这里面有大量细节问题,比如虽然识别出了字体是什么,但字体名称、大小、行高都没有,因此生成的页面肯定和原稿有很大出入。
如何识别出这些字体信息呢?如果都是中文倒是比较简单,因为中文都是方块字,除了「一」这样的字以外的绝大部分字都能根据文字高度推测出字体大小,而字体名称要准确会比较麻烦,还得单独弄个识别算法,或者直接都认为是黑体。如果字体是英文更麻烦,英文每个字上下高度变化太大,比如「a」「x」等是在 x-height 里的,有些延伸到 baseline 下面,有些延伸到 mean line 之上,需要保证的字母齐全,不然就没法算出文字的大小。


识别字体名称更是个成本不小的工作,这同样也能用深度学习的 CNN 网络来识别,Adobe 已经做了相关研究,最好的成绩是 70%,另外这个也取决于有哪些字母,比如 Hevetica 和 Arial 只有少数几个字母在边缘处有细微差别,如果正好没有那几个字母是无法区分的。
专业做前端的读者读到这里应该想吐槽了,这真是舍近求远,明明设计稿 psd 或 sketch 中直接就能读到字体信息,而且能保证 100% 准确率,为什么要这么折腾?难道是手上只有竞品页面截图。。。
基于图片有很多无法解决的问题,比如有重叠的情况,因为只有二维的信息是不够的,这也是为什么目标检测算法很难处理密集人群(Crowd)问题,比如只看到半个人脸,当然会认为那个不是个人。
如果你动手能力强,可以试试下载 Rico,它搜集了 6.6w 个安卓 UI 界面和对应的 XML,通过这么大的数据训练个 UI 识别自动生成代码应该不错,不过就是里面绝大部分 APP 界面的设计都很丑,在我看来没啥价值。。。
另外还有人拿来生成数据可视化大屏,本来我也想在 Sugar 中尝试,比如用户手绘一个大屏,然后自动识别图表并生成页面,这个技术要实现起来不难,但仔细一想发现使用成本更高,尤其是地图组件,就算大家最熟悉的中国地图,绝大多数人也不可能一笔画出来,不信你试试。。。而拖拽到页面中只需要 1 秒,所以这功能唯一的作用就是吸引眼球。
除了识别字体,还有另一个棘手的问题,那就是组件的组合,前面分析出来的结果是一个个独立的元素,比如文本、输入框、图片等,基于这些信息只能用来做绝对定位的静态页面,没法接入动态数据,而要转成流式布局,就需要引入很多人工规则来判断,这些规则写起来很容易顾此失彼,优化了某种情况又导致新的问题,让你不得不考虑:「还是去分析 psd 吧」。
强化学习
分析 psd 这个我们后面再谈,毕竟和智能没啥关系了,我们再看看人工智能里面还有什么技术可以用么?
有一个或许可行的是强化学习,强化学习这几年很火,比如掌握一切棋牌类游戏的 AlphaGo Zero、在星际争霸II 达到宗师段位、击败 99.8% 人类的 AlphaStar、在 Dota 2 中击败世界冠军和在 7000 场比赛中胜率 99.4% 的 OpenAI Five,还有在王者荣耀和网友大战 2100 场只输了 4 场的绝悟,看上去在游戏领域人类没希望了,如果有类似《安德的游戏》那样的训练环境,岂不是可以训练出胜率 99.x% 的机器人指挥官,在战争中碾压人类。
这些是如何实现的?以王者荣耀为,「绝悟」实现原理可以看 AAAI 2020 的这篇论文,它基于强化学习里常见的 Actor Critic 网络,使用 PPO 训练,用 GAE 来优化,收集了 500 年时长的人类对决数据,强化学习中很关键的是奖励设计,它参考自 OpenAI Five,但具体数值不一样,也体现出了玩着荣耀和 Dota 2 的不同:
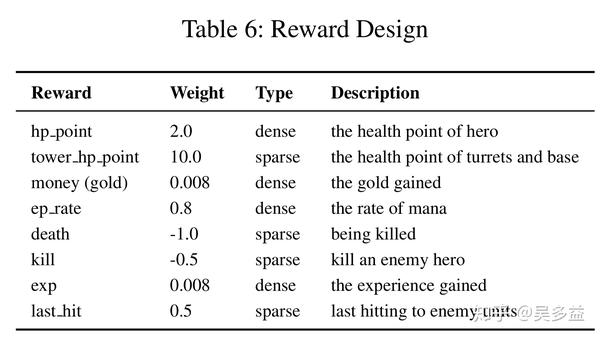

解释一下这个奖励设计是为了在训练模型的时候算出当前操作的结果是好是坏,好多少,这个值是零和的,比如血量,打对方的权重是 2,反过来被掉血就是 -2 了,可以看到塔血量的权重最高,接下来依次是英雄血量、被杀、法术量和补最后一刀,而击杀对方英雄的权重是负数,也就是说不仅不重要反而会拖累。。。腾讯这篇论文里没解释原因,在 OpenAI 那篇论文里也是负数,它的解释是击杀英雄获得的金币和经验足够多了,所以在这里削减一下,但实际效果还是正数,算了一下按 200 金币的话就是 0.008 * 200 - 1.0 = 0.6,还是明显低于打塔的,所以拿再多人头也没用,不积极拆塔就等着被翻盘,另外补最后一刀单独拿出来当权重了,说明是很关键的细节操作。
不过哪怕你细节拉满也打不过「绝悟」,因为它是通过内部接口获取到状态数据(小兵血量、英雄位置等)的,能同时了解所有信息,而你只能盯着屏幕,容易顾此失彼,如果太关注补兵和 1v1,就没空看小地图,不知道对方来支援了,而看小地图太多又会影响眼前的 1v1,所以在信息获取方面无法赶上「绝悟」。
强化学习训练的核心流程如下图所示:
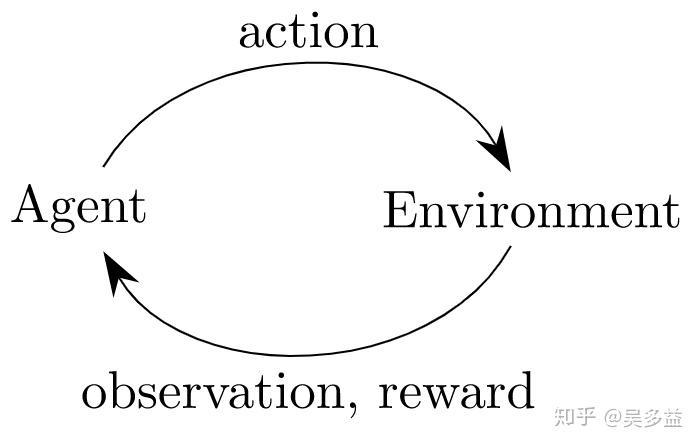

其中 Agent 可以理解为玩家,action 是操作(比如释放技能),Environment 是游戏,observation 是玩家观察到的状态(比如对方掉血了),reward 是获得的奖励(比如按前面的权重是 2.0)。
强化学习领域的算法太多了,我自己也晕,无法挨个解释,感兴趣可以看看《Reinforcement Learning: An Introduction》,不过那本书里绝大部分东西都只能用来做很简单的策略,前面提到的几个游戏用的都是 Policy Gradient 方法,而在这本书里只有 16 页,所以看我这本书也只是入门,要学习得花大量时间。
但作为工程师,倒是可以不用了解算法细节就能用,因为大部分强化学习都支持 gym 环境,只需要基于 gym 定制一个环境,就能使用这些算法来训练了。
自定义 gym 主要做的事情是明确操作列表和设计出奖励机制,是不是很简单?
import gym
from gym import spaces
class AlphaFEEnv(gym.Env):
def __init__(self, arg1, arg2, ...):
super(CustomEnv, self).__init__()
# 定义有哪些操作
self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS)
def step(self, action):
...
# 执行这个操作后算出结果好坏
return observation, reward, done, info然而,这两件事在切图场景下都很难,和王者荣耀不同,王者荣耀中的操作不多,就是买装备、移动、平 A、丢技能、回城、吃口药,切图的操作空间极大,难以穷举,而且相同的设计稿在不同需求下有不同的切法,比如没什么交互的页面甚至可以直接整图,而奖励机制也很难设计,无法准确判断一种切图方法和另一种切图方法究竟「差几分」,而这个分数是训练强化学习必须的,因此通用的切图很难,必须将问题缩小,限制到某个领域。
像淘宝就用在了 banner 设计上,因为场景专一,能做大量简化,使得操作空间可以穷举,比如设计稿分为了主图、修饰、文本等组件,然后对它们的操作主要是选字体、缩放、移动位置、调色等行为,在奖励机制方面,基于设计基本来来打分,比如配色的色相和布局的平衡等,同时还能根据线上点击率来辅助打分,因此可以使用强化学习。
正是因为强化学习对环境的依赖,使得目前研究几乎都是打游戏,因为游戏能很清楚算出分数,而要用在现实世界必须想办法将操作空间缩小,将收益量化。
基于设计稿的自动切图
前面提到通过图形学的方式成本高效果也不好,不如直接基于设计稿解析,在设计稿中能直接得到图层和文本信息,不仅省去大量工作,效果也肯定比直接基于图片好。
很显然你不是第一个想到这种方式的,好多好多年前我就知道有人做了,我们自己也在 5 年前就在 h5.baidu.com 里加入了 PSD 切图功能,不过它更像是一种辅助,帮你把各个图层导出为图片或解析出文本信息,然后放到页面中对应的位置上,虽然和智能没啥关系,但确实能大量节省时间,所以很受欢迎。
解析方面最简单的方法是写插件,尤其是 psd 开源解析库都不完善,而且即便能读出图层样式,也得自己实现一遍这些样式才能正确输出图片,太麻烦了。sketch 相对好点,它的格式是 JSON。
不过基于设计稿也有头疼的问题,因为正常的 psd 文件图层长这样:

其实也不是设计师懒,如果你也做过设计就理解了,设计不像写代码可以提前想清楚,在设计过程中经常想什么改什么,导致经常复制一个图层改改,换成你也懒得每次都命名。
如果这样的图层结构拿去生成代码,肯定是 garbage in, garbage out,只能拿来做原型,所以需要让设计师配合,在交出设计稿的时候做一次预处理,调整层次结构,加命名规范等,这方面有个产品是 Yotako,看一眼它的例子就知道了:
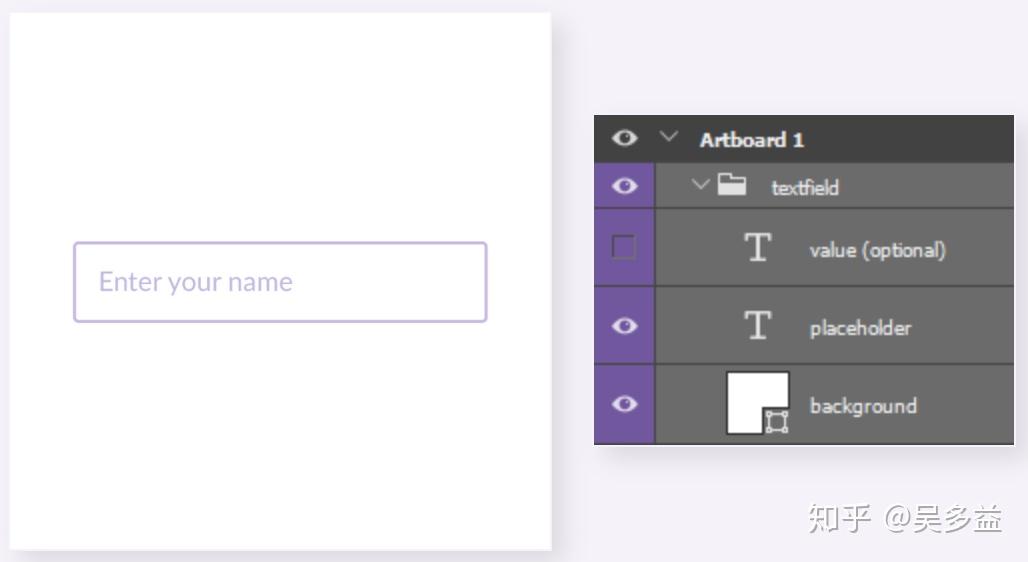

通过层级关系和命名,可以准确识别是个输入框,然后那段文字其实是 placeholder,很简单,但如果是输出图片用前面的机器学习方法将非常麻烦,还得弄个文本分类判断是不是 placeholder。
然而这个命名规范是个双刃剑,虽然能让切图更准确,但导致了场景受限,换个复杂点的例子就不知道要怎么命名了。
转成易于分析的图层结构后,接下来解析主要就是做几件事情:
- 图层结构的遍历,按约定的命名规范来生成代码嵌套结构。
- 找出文本,读取出字体信息,这点就比前面图片识别强多了,准确率 100%,还能分辨出换行。
- 有图层样式的,能用 CSS 表示的用 CSS 表示,比如矩形加背景就能用 div 表示而不需要生成一张图片,但大部分图层样式不能转成 CSS,所以复杂的图层最好预先栅格化。
- 计算出这些元素对应的位置,最简单是转成绝对位置,或者换算出 flex。
- 还有好多细节,自己实现一遍就知道。
这种方案可以在某些场景下提升效率,然而它有很多问题难以解决的,比如响应式布局,它需要真正理解设计稿的意图,比如宽度拉长的时候,是左右固定中间可变,还是从 3 列变成 4 列。
加上生成代码无法做到语义化,所以我们只用来辅助开发运营类的页面,要想能直接在线上使用,最好的方式依然是「组件化」。
组件化
其实到了前面那个方案,就已经不能叫「智能」了,设计稿导出 html 我十几年前就用 Adobe Fireworks 做过,还支持雪碧图和九宫格圆角呢,所以反倒是 Airbnb 把 React 转成 Sketch 的插件有点意思,解决了设计稿混乱的问题,不过对设计师有一定要求。
再退一步就是基于组件化的方式了,这是目前所有大一点的前端团队都会造的轮子,和智能不沾边。
尽管不「智能」,但组件化依然是目前的最好方案,也是我们现在的主要做法,这方面我们有两个产品:AIPage 和 AMIS,分别用于站点页面和后台页面的开发。
AIPage 主要用于网站开发,内置了几百种页面组件,通过这种大量枚举的方式,可以做到大部分常见页面可以直接组装出来,也能像 Photoshop 那样自由拖拽设计页面。

AMIS 是前端低代码框架,目前已经开源,它在百度内部已经使用了 4 年多,制作了 3w 多页面,这些页面大部分由后端开发者制作的,节省了很多前端开发成本,为什么后端就能做?因为它是基于 JSON 生成页面的,而且还有可视化编辑器:

不要一看到用 JSON 就认定灵活性差,amis 可以很方便地实现组件之间的联动及各种交互效果的,掌握好了可以快速制作大量复杂的后台页面,值得花时间研究。
结论
不仅是 GPT-3,所有现在的 AI 技术都不可能取代前端切图,只能在限定领域提供些辅助,比如代码自动完成提示、生成类似 H5 传单这种静态内容为主的页面,目前取代切图最好的方案是组件化及类似 amis 这样的低代码平台。
而要想实现真正的智能切图,就得解决强人工智能(AI-complete)问题,别看现在很多方案号称准确率 7-80%,看着快接近了,其实剩下那 20% 是强人工智能问题,且不说这个问题恐怕永远解决不了,最大的悖论是如果你能解决,都可以能造出天网了统治人类了,还切啥页面呢。